
대용량 압축하여 서버에 저장하지 않고 사용자에게 다운로드로 보내기
이번 프로젝트에서는 대용량 파일들을 압축해서 다운로드하는 기능을 만들게 되었다. 처음에는 항상 하던 대로 했다.
- 파일을 압축하여 서버에 저장한다.
- 저장되어 있는 파일을 다운로드한다.
이와 같은 방식은 바로 문제점이 나타났다.
- 압축 파일 당 10GB라고 가정하면 사용자 10명이 다운할 때 100GB를 저장 할 공간이 서버에 있어야 한다.
- 압축 후 파일을 저장, 그리고 삭제하면서 IO 사용을 많이하여 문제가 발생한다.
- 문제가 두가지로 끝나지 않는게 더 문제, 기타 등등
더군다나 다운로드를 하면 2GB까지만 다운로드를 하는 문제가 계속 발생했는데 그건 response.setContentLength로 제한을 걸어버렸기 때문이다. byte 형식이 한 번에 2GB까지 밖에 되지 않았고 이를 fileinputstream.available()로 지정해놓다 보니 2GB 밖에 다운로드 되지 않았다. 즉 파일의 크기가 유동적으로 변하면 response.setContentLength와 같이 길이를 지정해놓을 이유는 당연히 없다.
이러한 이슈들을 해결하기 위해 개선 방안을 조사한 후 확정 지었다.
- zip4j zipOutputStream을 사용하여 서버에 저장하지 않고 사용자에게 바로 보낸다.
위와 같은 방식을 사용할 때 장점은 아래와 같다.
- IO 사용을 기존 방식에 비해 덜 하기 때문에 디스크 용량 및 IO 과부하 문제는 걱정하지 않아도 된다.
- 동시 사용자가 사용하더라도 기존 방식에 비해 서버 자원을 크게 사용하지 않는다.
그렇다면 정말로 개선됐는지 어떻게 확인할 수 있을까
여러 방법이나 툴이 있겠지만 나는 top 명령어를 사용했다.
top 명령어를 사용하면 누구나 쉽게 기능이 동작하는 동안 서버가 어떤 자원을 어느 정도 사용하고 있는지 확인할 수 있다.
기존 방식

기존에는 사용자 1명을 기준으로 테스트 했음에도 압축 90% 지점을 보면
CPU 사용률 : 24.1%
load average : 1.11, 0.60, 0.37 (최근 1분, 5분, 15분 시스템 평균 부하율)을 기록하고 있다.
물론 1분 단위에서만 1.00을 넘었고 5분과 15분에서는 1.00 이하를 유지하고 있기에 문제가 되지 않아 보이지만 사용자 한 명만 사용해도 이 정도라는게 문제점이다.
개선 방식

개선 방식은 사용자 3명을 기준으로 테스트하였으며 비슷한 지점에서 측정한 값을 보면 확연히 차이가 난다는 것을 확인할 수 있다.
CPU 사용률 : 9.1%
load average : 0.32, 0.36, 0.34 (최근 1분, 5분, 15분 시스템 평균 부하율)을 기록하고 있다.
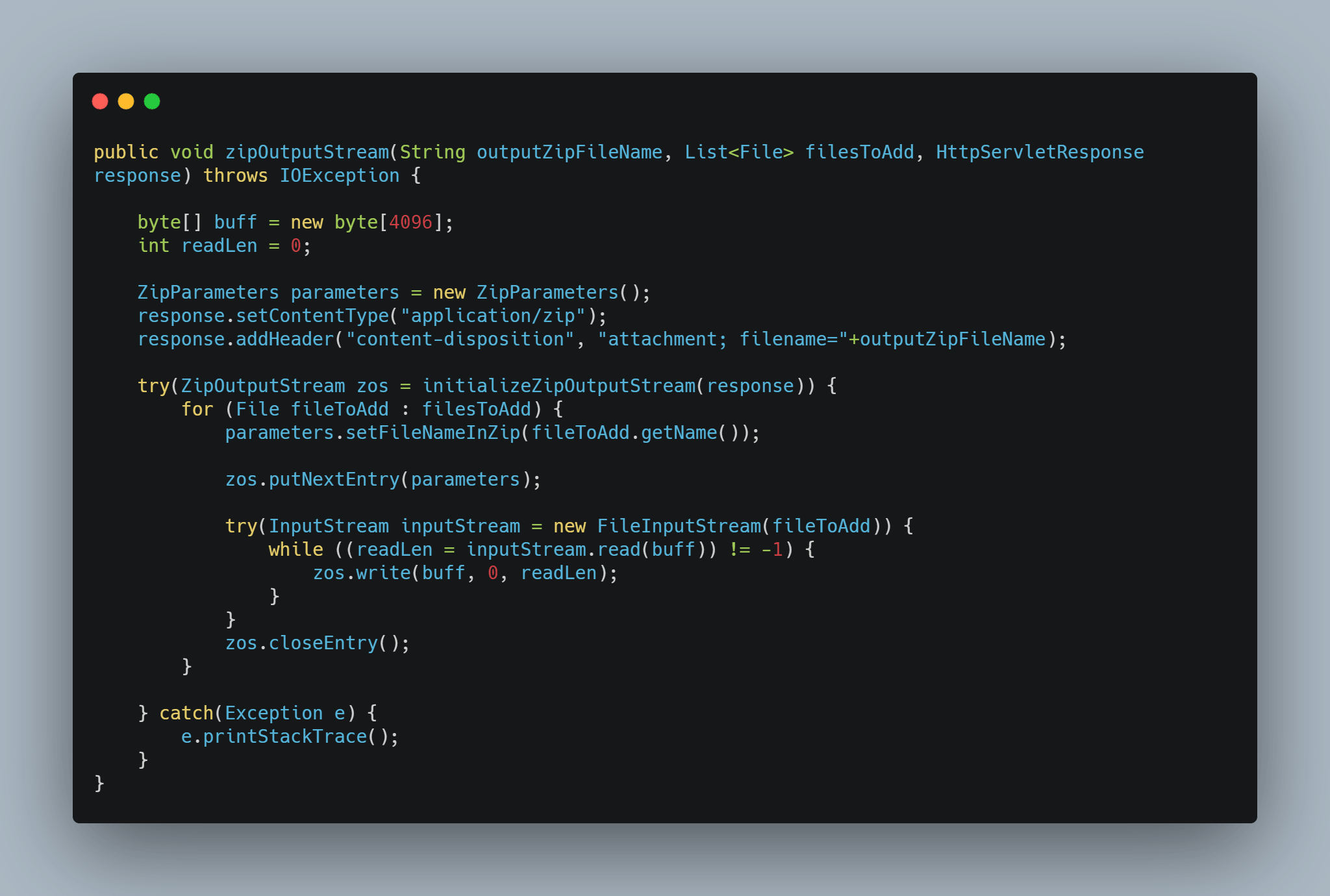
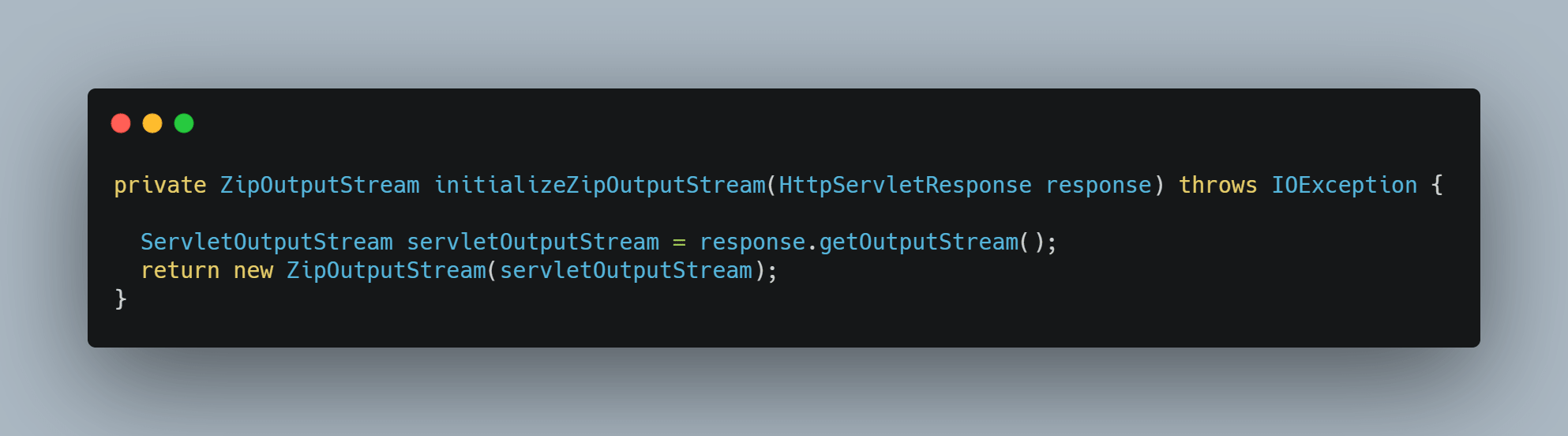
사용한 코드는 아래와 같다.
zip4j에서 올려놓은 예제 코드를 내 상황에 맞게 조금 수정했다.
outputZipFileName은 결과 압축 파일명 파라미터이다.
filesToAdd는 압축할 파일들 파라미터이다.
사용 예제는 아래 있다.

정말로 이게 최선의 방법인지는 자신이 없지만 조금이라도 나은 기능을 만들었다면 개인적으로는 만족한다.